Using two sided stencil volumes to improve fill rate with deferred lights is not new; I'll write more if anyone wants, but this is all stuff I got off of the interwebs. The high level summary:
The simple solution is obvous: use GL_depth_clamp to the near and far clip planes instead of clipping. But what if you don't have this extension?
In these pictures, we are seeing only a close rendering of the P180 - the far clip plane is just off the end of the airplane. The red cone extending from the tail is the pyramid light volume for the tail light that is shining out from the tail - it illuminates the top of the plane.
In the three pictures the far clip plane is progressively moved farther away. The lighter colored square is the missing geometry - since the pyramid is clipped, you're seeing only the top and sides of the pyramid but not the base. This is the area that will not be correctly stencil counted or rasterized.

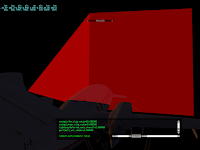
Here we can see why this is a problem. Note the vertical line where the back face is missing. When we actually rasterize, we don't get any light spill - the result is a vertical clip in our light, visible on the top of the fuselage.
If depth clamp isn't available, one alternative is to restrict the Z position of each bounding volume vertex in clip space. This can be done in the vertex shader with something like:
What's nice about this hack is that it is entirely in vertex shader, which means that we don't do anything that could inhibit the GPU's ability to do early or optimized Z culling.
The actual screen-space position of the view volume does not change. This is because the position edit is done in clip space, and clip space is orthographic - X and Y turn into raster positions and Z into a depth position. The "perspective" is created by dividing X and Y by W - we're free to completely whack Z without deforming the geometry as long as we are post-frustum-transform.
Wel, not completely free. There is one hitch: the actual Z test is no longer correct. Observe these two pictures:
 In the first picture, we see the correct Z intersection of the view volume with the fuselage. (This picture is normal rendering with a close far clip plane, hence the lack of a pyramid back.) The area of the fuselage that is not red is outside the light bounding volume, and there is just therefore just no need to shade it.
In the first picture, we see the correct Z intersection of the view volume with the fuselage. (This picture is normal rendering with a close far clip plane, hence the lack of a pyramid back.) The area of the fuselage that is not red is outside the light bounding volume, and there is just therefore just no need to shade it.
Now look at the second picture - this is with Z clamping in the vertex shader. Because the Z position has been clamped pre-interpolation, the Z fragment positions of any face that partly extended outside the clip planes will be wrong!

In the picture we see this in the form of incorrect volume intersection. Because the far end of the pyramid has been moved closer to us (to keep it inside the far clip plane) the fragments of the entire pyramid are too close to us - almost like a poor-man's polygon offset . The result is that more of the fuselage has turned red - that is, the Z test is wrong. The actual Z error will sometimes reject pixels and sometimes accept pixels, depending on the precise interaction of the view volume and the clip planes.
The net result is this: we can hack the Z coordinate in the vertex shader to guarantee complete one-sided rasterization of our view volume even with tight clip planes and no depth clamp, but we cannot combine this hack with a stencil test because the stencil test uses depth fail and our depth results are wrong.
Thus the production path for X-Plane is this:
- To save fill rate when drawing deferred lights, we want to draw a geometric shape to the screen that covers as few pixels as possible - preferably only the ones that will be lit.
- Typically this is done using either a billboard or a bounding volume around the light. X-Plane 10 uses this second option, using a cube for omnidirectional lights and a quad pyramid for directional lights. (This is a trade-off of bounding volume accuracy for vertex count.)
- If we have manifold bounding volumes, we can select only the fragments inside the volumes using a standard two-sided stenciling trick: we set the back face stencil mode to increment on depth fail and the front face stencil mode to decrement on depth fail - both with wrapping. The result is that only screen-space pixels that contain geometry inside the volume (causing a depth fail on the back face but not the front face) have an odd number of selections.
- Once we have our stencil buffer, we can simply render our manifold volumes with stencil test to discard fragments when our more expensive lighting shader is bound.
- If the front of the volume intersects the near clip plane, that's no problem - the front facing geometry isn't drawn, but since there was no geometry in front of our light volume (how could there be - it would also be on the wrong side of the near clip plane too) this is okay.
- We need to render the back face only of our volume to correctly rasterize the entire light. If we rasterize the front, we'll draw nothing when the camera is inside the light volume, which is bad. (This need to handle being inside the shadow volume gracefully is why Carmack's Reverse is useful.)
- When drawing the actual light volume, we're going to lose a bunch of our screen-space coverage, and the light will be missing.
- When we're using stenciling, the increment/decrement pattern will be broken. If we have geometry in front of the entire light, it will end up off-by-one in its surface count. This in turn can interfere with other lights that cover the same screen space.
The simple solution is obvous: use GL_depth_clamp to the near and far clip planes instead of clipping. But what if you don't have this extension?



In these pictures, we are seeing only a close rendering of the P180 - the far clip plane is just off the end of the airplane. The red cone extending from the tail is the pyramid light volume for the tail light that is shining out from the tail - it illuminates the top of the plane.
In the three pictures the far clip plane is progressively moved farther away. The lighter colored square is the missing geometry - since the pyramid is clipped, you're seeing only the top and sides of the pyramid but not the base. This is the area that will not be correctly stencil counted or rasterized.


Here we can see why this is a problem. Note the vertical line where the back face is missing. When we actually rasterize, we don't get any light spill - the result is a vertical clip in our light, visible on the top of the fuselage.
If depth clamp isn't available, one alternative is to restrict the Z position of each bounding volume vertex in clip space. This can be done in the vertex shader with something like:
gl_Position.z = clamp(gl_Position.z, gl_Position.w,-gl_Position.w);(W tends to negative for standard glFrustum matrices.)
What's nice about this hack is that it is entirely in vertex shader, which means that we don't do anything that could inhibit the GPU's ability to do early or optimized Z culling.
The actual screen-space position of the view volume does not change. This is because the position edit is done in clip space, and clip space is orthographic - X and Y turn into raster positions and Z into a depth position. The "perspective" is created by dividing X and Y by W - we're free to completely whack Z without deforming the geometry as long as we are post-frustum-transform.
Wel, not completely free. There is one hitch: the actual Z test is no longer correct. Observe these two pictures:

Now look at the second picture - this is with Z clamping in the vertex shader. Because the Z position has been clamped pre-interpolation, the Z fragment positions of any face that partly extended outside the clip planes will be wrong!

In the picture we see this in the form of incorrect volume intersection. Because the far end of the pyramid has been moved closer to us (to keep it inside the far clip plane) the fragments of the entire pyramid are too close to us - almost like a poor-man's polygon offset . The result is that more of the fuselage has turned red - that is, the Z test is wrong. The actual Z error will sometimes reject pixels and sometimes accept pixels, depending on the precise interaction of the view volume and the clip planes.
The net result is this: we can hack the Z coordinate in the vertex shader to guarantee complete one-sided rasterization of our view volume even with tight clip planes and no depth clamp, but we cannot combine this hack with a stencil test because the stencil test uses depth fail and our depth results are wrong.
Thus the production path for X-Plane is this:
- In the "big" world we use two-sided stenciling.
- In the "small" world if we have depth clamp we use two-sided stenciling and depth clamp.
- In the "small" world if we don't have depth clamp we use vertex-shader clamping and skip stenciling.












{kind=link}